I've been trying out a couple of new read-later apps recently: Matter and Reader by Readwise. I do all my RSS and read-later reading on iOS, mostly on an iPhone. I currently use Reeder 5 for RSS and Goodlinks for read-later.
I did a couple of interesting experiments to test the differences in article parsing between these apps, and thought it was worth sharing the results.
My current reading setup
Feel free to skip this section entirely! It's just some context on what I use right now and why I was interested in trying Matter and Reader.
There are a couple of things that aren't quite perfect about my current setup that make me open to checking out new options. Reeder doesn't have a way to use the share sheet from safari to search for and subscribe to new RSS feeds. It can open RSS feeds from Safari, but doesn't always—I'm not sure what the difference is, but there must be a particular type of URL that it can handle. Unread is another iOS app for RSS feeds that does have this feature—you can share any URL from Safari and Unread's extension will try to find any RSS feeds on that site, and let you subscribe to them. In Reeder, I have to manually copy the URL, open Reeder, navigate to the screen for adding a new feed, and paste it in. It's not terrible, but it's a lot more friction.
Another thing I'm looking for is highlighting. Neither Reeder nor Goodlinks support highlighting or annotating articles, and I've recently found myself wanting to do this.
Goodlinks thankfully has a Firefox extension, so I can easily share to it from my Mac, but Reeder only comes with a Safari extension—and that's part of the Mac version, so I'd have to pay for the Mac app just to have the extension just for Safari. Reeder has a read-later option built-in, which I love, because it's nice to have all my reading in a single app, but it's not easy enough to save links to Reeder from my Mac, so I don't really use this feature.
Parsing test 1
I tried saving this article to Matter recently and found it couldn't parse it at all. Matter defaulted to showing me a web view of the article (i.e. what I saw in my browser before I saved it), and when I forced it to show me the reader view, the content was empty.

I don't know why Matter struggled with this article so much (I reported it to the Matter team), but it made me curious about whether this site was doing anything particularly odd. So I tried saving the same article to Reader, Reeder (using the read later feature), and Goodlinks to compare.
The article is about Japanese grammar, so it has some Japanese text to render, including some sentences inside tables with English translations, but otherwise it's fairly basic.
Goodlinks had no issue at all.


Nor did Reeder, though it did render the <table> (inside a <figure> tag) in a very pale grey for some reason.
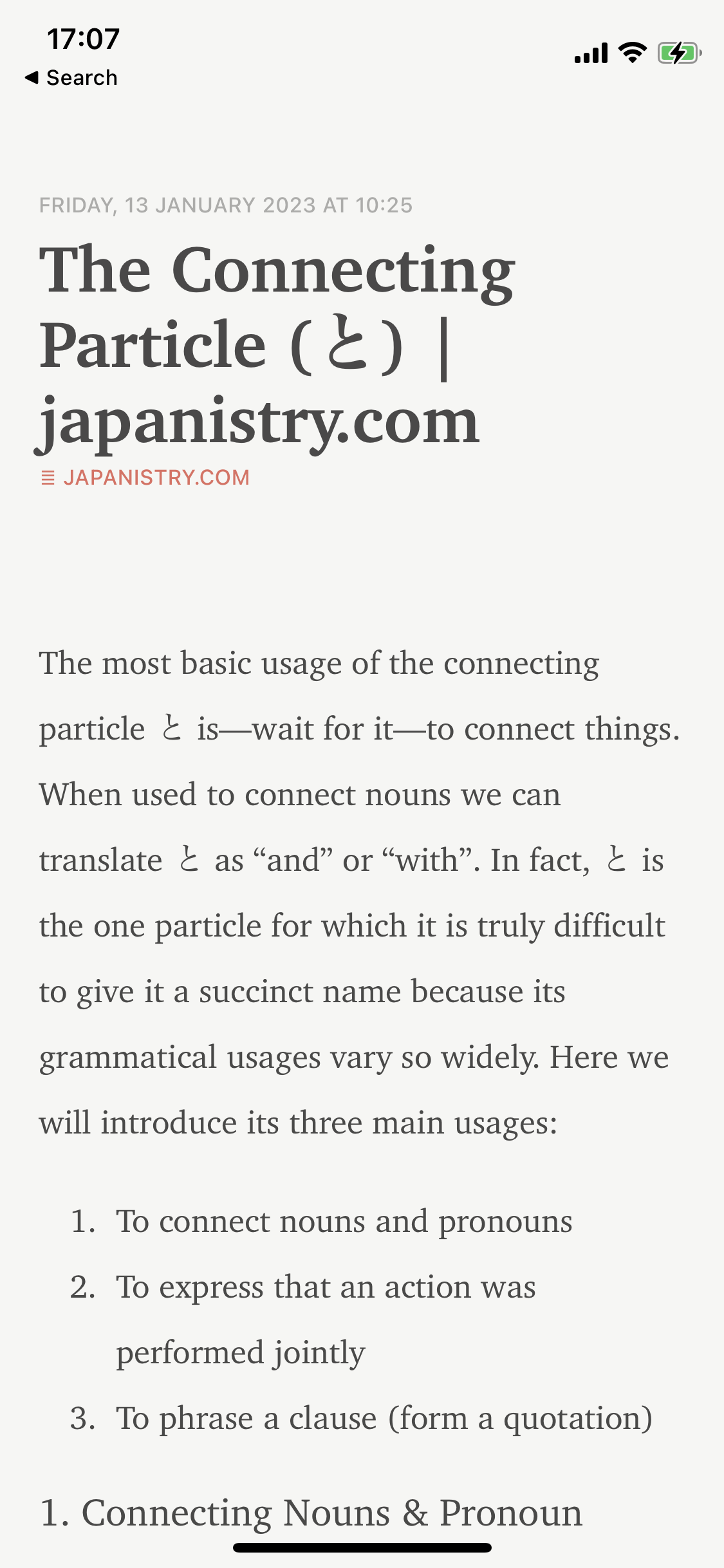

Reader parsed the text, but completely left out all the Japanese/English sentence examples (I'd already added some highlights before taking this screenshot, but they're not relevant to the point about parsing). The second screenshot below is the exact same part of the article shown in the Reeder screenshots above—you can see that all the Japanese example sentences are missing entirely in Reader.


Parsing test 2
Earlier this week I saw that the GRDB library had some new/updated guides in the documentation. I wanted to save them for reading later, but I wasn't sure how well a Markdown file from GitHub would be parsed. Because I anticipated parsing issues, I was curious to test out all four apps again and compare the results.
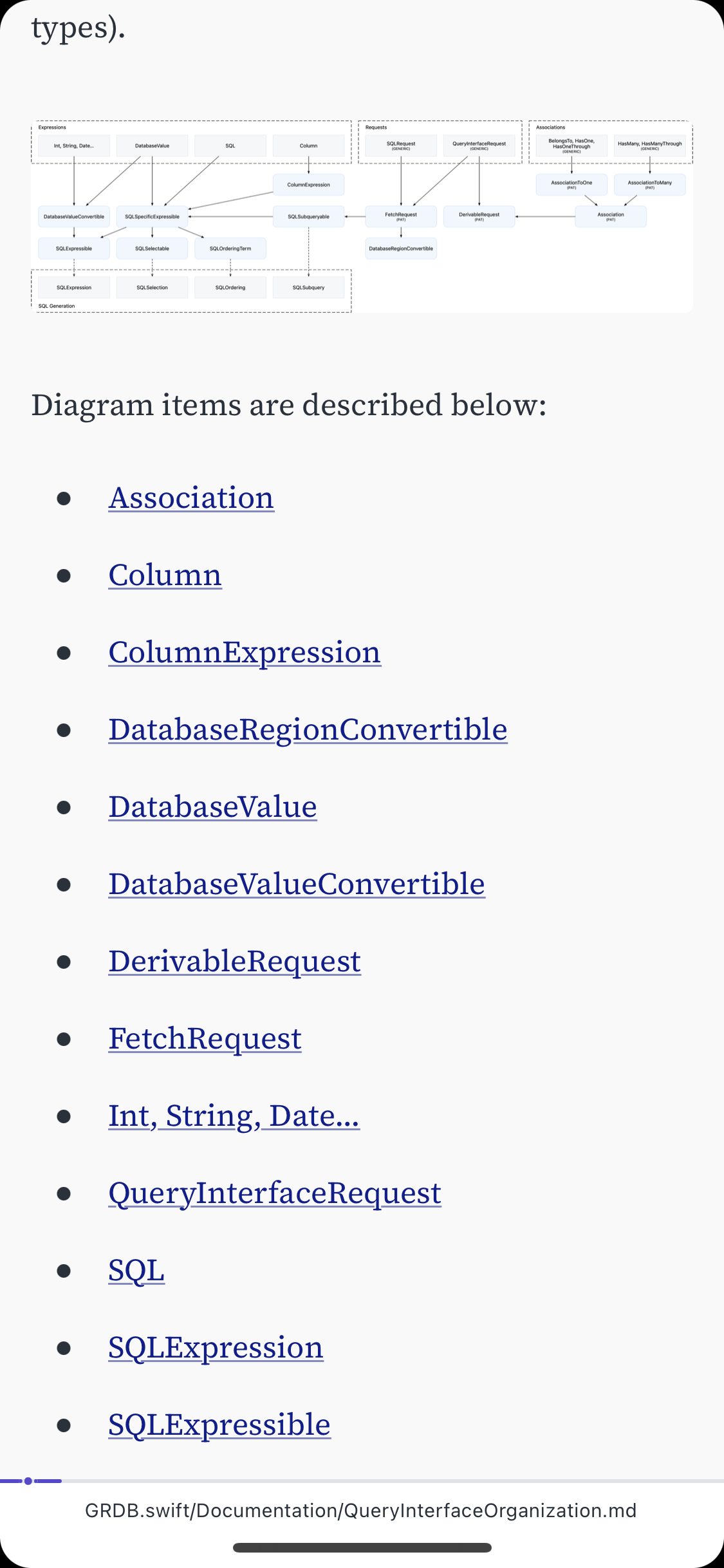
Here's the GitHub link I tested. It's a Markdown file hosted on GitHub. It starts with some plain paragraphs, then an image, then a long <ul> before continuing with paragraphs and small code blocks.
Goodlinks struggled with this one.


After some digging into the source, it looks like Goodlinks completely ignored any <a> with a relative href, which is why there's only one <li> displayed in the whole <ul> and the rest are blank. There are also links missing in the text, such as the end of the first paragraph after the heading "Association", where Goodlinks shows the text "It conforms to .", where there's an <a> with a relative href missing right before that full stop.
In terms of code blocks, which are often iffy when reading an article that's been parsed from the web, Goodlinks doesn't have any syntax highlighting but does parse these correctly and renders them with a different background colour and horizontal scrolling so they're easy to read.
The Markdown file has an <h1> with the text "Query Interface Organization", while the webpage's <title> element has the text "GRDB.swift/QueryInterfaceOrganization.md at master · groue/GRDB.swift". Goodlinks was able to pick up both of these, ignoring the <h2> on the page which is actually GitHub navigation, and not part of the Markdown file I wanted to read, and showed them both at the start of the article.

Reader did a better job of parsing the contents of this article, with all the <a> elements included. It also rendered the code blocks as well as Goodlinks did.

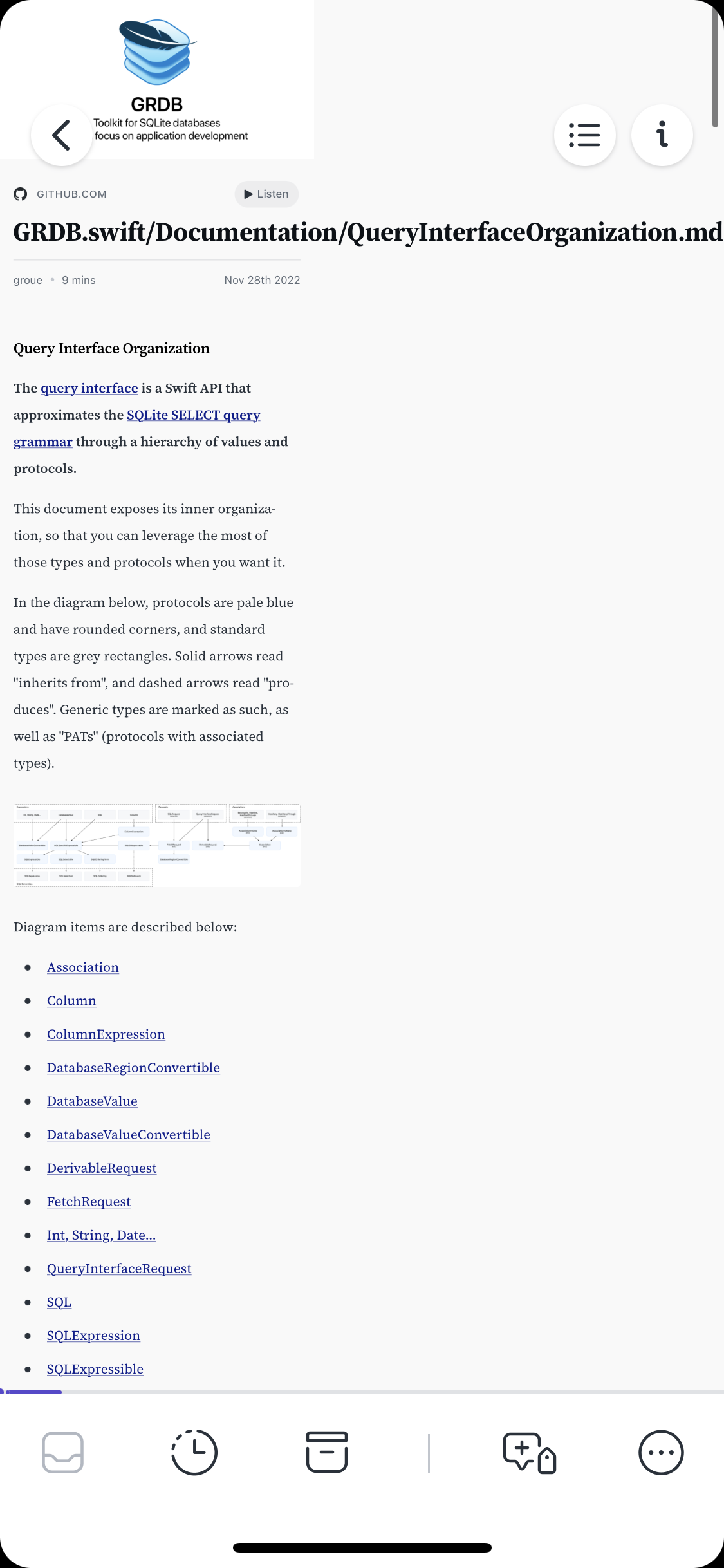
Reader did render the title of the article weirdly, though. It picked up the page's <title> but for some reason didn't wrap this text, so it ended up being twice as wide as the rest of the article when rendering. This meant the article view in Reader had a bunch of white space to the right of the article content, which added horizontal scrolling and really messed up Reader's navigation that relies on swiping from the left and right sides of the article view.

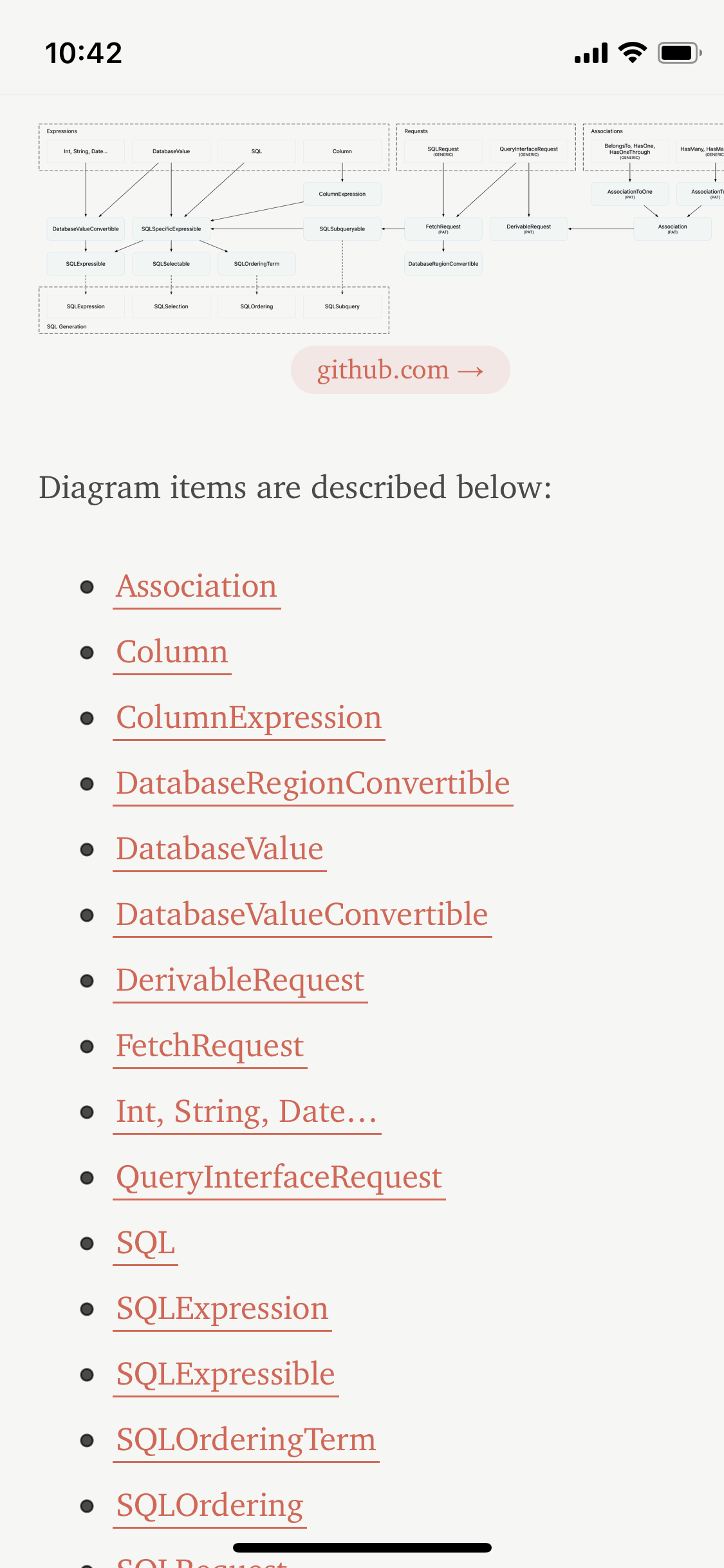
Reeder was able to wrap the title of the article, and didn't strip out <a> elements with relative hrefs. It also had no trouble rendering the code blocks.

Matter also had no trouble with relative hrefs, and wrapped the title correctly. It managed to parse code blocks, and even rendered them with syntax highlighting (chef's kiss), but the font is tiny, as is the line-height, and neither one respond to the in-app font-styling options, so I found these pretty hard to read.

Not only that, Matter had a weird issue where it didn't recognise any code block that started with a comment, so these were just rendered as normal text, which is gross and offensive to read.


My conclusion is that parsing articles from the web must be hard. No doubt there are a lot of heuristics here, and there aren't enforced regulations to make every website follow the exact same structure (nor would we want that), so it's impossible to parse every single URL correctly every single time.
But from these experiments (plus a bunch of other random tests I didn't keep careful track of), I think Reader and Reeder have the best parsing engines for the kind of content I save. I don't save Twitter threads, or Medium posts, or videos or podcasts, or lots of other things, so I only know how they work for my needs, but they seem the best for me.
Reeder is also super quick to parse new articles, perhaps because it's all local, and doesn't rely on a server. Reeder also feels like a native app, as does Goodlinks, whereas Matter and Reader feel like they're using web technologies. They don't conform to iOS conventions as consistently, and they don't feel quite as snappy.
I don't have any particular recommendation for any of these apps, but I just wanted to share what I noticed when experimenting with them recently.